As I had previously explored, there is now a great potential for anyone using commodity hardware, even that which can be purchased at your local Costco, to enable sovereign AI capabilities. From simple code generation inside Visual Studio Code, to generating function-level code blocks based on prompts of desired functionality, to doing in-depth security analysis of source code, an individual is not necessarily tied to a SaaS service to experience significant value. As you might recall, my goal in these rudimentary tests was to do a simple, unscientific “gut check” of what could be expected, not inventing a new measurement baseline. My testing platform is a relatively humble Nvidia RTX 5070 Ti running in a Costco-sold gaming machine. The results were surprising enough that I was able to cancel my subscription to my original AI provider of choice; although it required some Python elbow grease. Let’s explore it a bit more…
It seems apparent that there are many reasons that enterprises and individuals are using, and aggressively seeking growth in AI. At the risk of oversimplifying what I know is a complex, even geopolitical situation, I think that they can be roughly divided into a few groups:
- Corporate Growth – This group, which in my opinion comprises most companies in the western world, is seeking to optimize their corporate structure and improve profits by replacing a varied number of roles in the company with AI-companions and AI tools to enable the remaining individuals for higher levels of productivity. With the bottom-line driving the corporate world, this is to be expected. However, as mankind was created to work, where this ends and what the consequences end up being is anybody’s guess. I’ll save my further thoughts on that for content later on.
- Information Assistants – This group, including myself, includes individuals that realize AI, specifically LLMs, are here to stay, and do make an exceedingly useful tool in our arsenal to enhance our skills and experiences to achieve our goals. From this perspective AI is neither “the greatest thing since sliced bread”, nor is it as many fear “the end of the world”. Instead, it, much like the car, or Google Search, is simply a new tool to make information more accessible, which comes accompanied with a need to be used responsibly.
- Customizable Relationships – This sector is probably the most lamentable, where individuals are not necessarily seeking to have healthy human relationships as God intended. Instead, their focus is on having a self-orbiting experience that is enabled by having a trained, sudo-human experience with a computer focused on their same goals.
- Super Intelligence – This group is hoping that AI can ultimately provide a god-like level of all-knowing intelligence. It’s the ultimate unicorn, that has billions of dollars invested in attempting to make this new Tower of Babel come to fruition. However, as close as we think we will get to being omniscient, we must remember that only Yahweh God is truly omniscient, it was He who made the heavens and the earth. Never-the-less, history continues to repeat itself.
That said, there are a myriad of opinions about AI and I won’t dive into too many details here, but the drive for progress here is multi-faceted, with my understanding being the root of this drive resting largely in a geopolitical, virtual arms race between the United States and China. Regrettably though, nobody wins an arms race, though there is always a biggest loser and indeed something significant will be lost by that side. Much like the corporate “race to the cloud” has started to rightfully swing back to the more economic self-hosted model, this “race to AI” will eventually swing back to more realistic expectations and use cases that provide 80% of the value, for 20% of the cost. Hopefully I’ll be able to share more thoughts about that later.
That said, I’d like to share my own attempts in making open source software and commodity hardware into a useful personal information assistant! My home network is much like an enterprise, with a couple internet-facing services behind a single gateway, with the expected supporting services such as a SIEM (Security Onion), firewall (forwarding all network traffic to SIEM), HIDS (Wazuh/AIDE), split-zone DNS with filtering, etc. As part of this micro-enterprise, I’ve identified and implemented a few exceedingly useful integrations.
Generic Chat Interface
Having a device with a GPU can be useful, but its usefulness is limited by its accessibility. Having to make use of a terminal to interact with the LLM is not helpful in many cases. To make it accessible to multiple devices and individuals I created a simple chatbot that has a few routing rules for input. There are many ways to do this, however, my personal platform of choice is NextCloud Talk, which comes with the ability to do external integrations with bots. Regardless of what platform you use, the basics are the same as you interact with your chat provider over their APIs. However, the beauty of using a mature chat provider is that your authentication/authorization is handled by the chat provider, so all your chatbot needs to do is validate the incoming information from the webhooks.
So now, simply by using an @ mention to my bot, I can specify one of several models that I’d like to query with generic chat messages. As you see below, this works to bring back results from the GPT-OSS:20b model in the chat-supported Markdown format.

Or, by changing the prompt preface, the Qwen3:14b, Gemma3, or any other model available on the LLM-host can be quickly reached and queried.
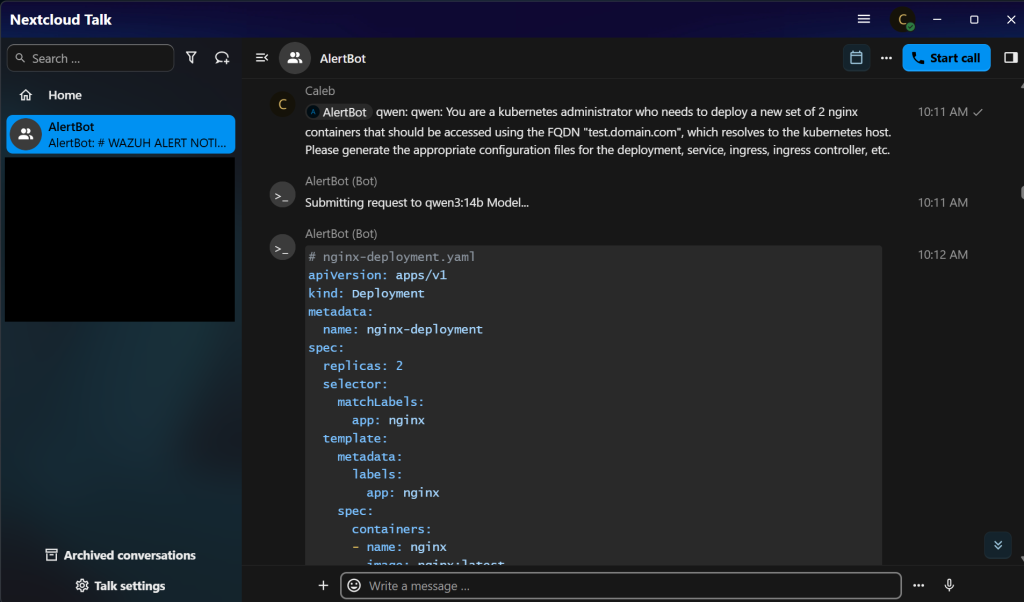
This chat capability provides most of the functionality that I desire from a LLM. Ultimately, it’s what allowed me to cancel my subscription to a SaaS Service and run everything literally in-house! While it’s certainly not as powerful as the most recent subscription models, it certainly hits the 80% value mark in my estimations.
Generic Task Automation
As useful as an LLM is in providing information, it’s simply a component in accomplishing a goal. While not directly related to LLM capabilities, one other useful aspect of on-demand chat-based functionality is the ability to run pre-determined tasks. For example, to assist in network troubleshooting there’s a simple workflow that can be called to return the results of key infrastructure assets. Nothing really new here by itself, but another small piece of a much larger puzzle.
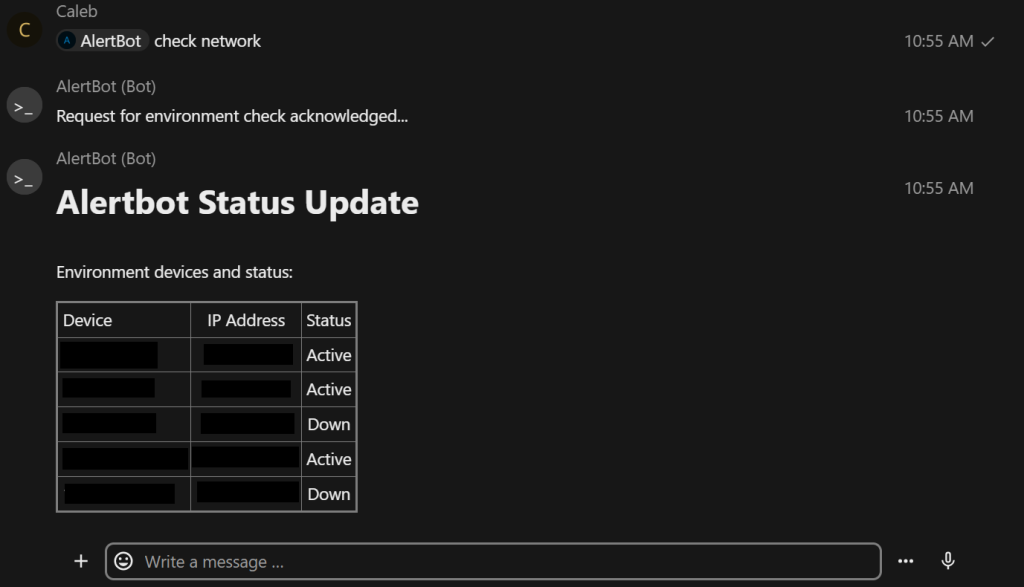
Security Alerts and Triage
While being able to do simple LLM chat tasks, or run pre-defined tasks is nice, it’s only the start of effective LLM integrations. Previous to my efforts with a chatbot, my home security review process was roughly equivalent to manually reviewing high-severity alerts every week or so. This manual process only covered the most urgent alerts from both Security Onion (SO) and Wazuh. This process takes a while, since SO watches all network traffic (including on the untrusted internet side), as well as ingesting logs from my servers. Thankfully much of it turns out to be benign, however, sometimes it requires significantly more investigation. Side note, when you monitor your home network traffic, don’t be surprised when you find your treadmill communicating with Alibaba cloud in China…
That time-consuming process however, has largely been mitigated with the chatbot being connected to the underlying events, as well enabled to communicate with my local LLMs. Now, as alerts come into the SIEM they are automatically filtered so that high-priority events receive an initial triage analysis by the LLM and then are forwarded to me via chat as they occur. Now, with a glance at my phone I can tell if an alert for something that is currently happening is for a run-of-the-mill reconnaissance/exploitation attempt, or, if it’s something that requires my immediate attention and response! You’ll notice in the screenshot below that there is the a cell for Triage Summary that includes the LLM’s analysis of the threat in all its available context.
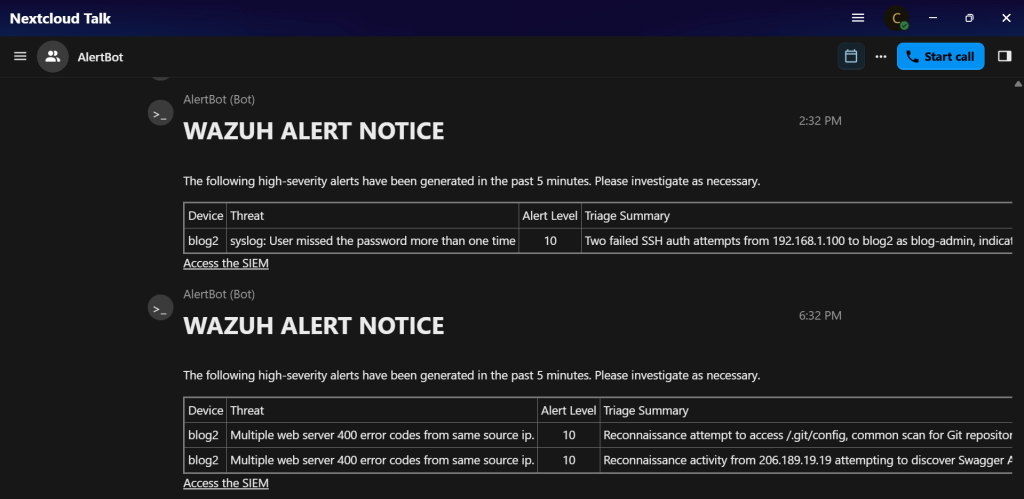
Having an LLM in your toolbelt is somewhat of a necessity for effective competition in today’s world. Regardless if you are looking for corporate growth and user enablement on a larger scale, or, simply a personal information assistant, they represent a significant enablement asset. No one individual can have the breadth of knowledge that even open source models provide. That said, with the specs and availability of today’s hardware you are not limited to reliance on a subscription model, or hardware that exceeds tens of thousands or millions of dollars. It’s my opinion that an individual, or business can experience a significant benefit from the planned and effective use of commodity hardware and open source models.