Before we started our journey to low code we knew that there were going to be areas that we had to mitigate in advance if we were going to be successful. The core of many of these was around the ability to capture the “low-code output” as actual code and storing it in our own git-based source control repository. This was a fundamental requirement during the selection process and we’re still very glad to have held to it. The benefits have paid large dividends in a couple key areas:
- Ability to have multiple branches and associated Salesforce sandboxes for testing
- Ability to change our merging strategy mid-stream
- Ability to cherry-pick configuration hot-fix changes and yet have a cohesive pipeline strategy
- Ability to make code-based changes without Salesforce Scratch (development) orgs
What Do We Have Here?
Ok, here’s the initial assessment of the situation as it existed when we started. We have a couple components, the first is the Salesforce.com production instance, from which we can create sandbox instances for testing. The next component is the multitude of Scratch (Development) Orgs that our users will be deploying via SalesforceDX. For more details please see my post on SalesforceDX Development. However, for the scope of this post we now know what components are at play. The process to develop is roughly as described below:
- Use SalesforceDX CLI to Connect to Production Instance
- Use SalesforceDX CLI to deploy new Scratch Org (with change tracking)
- Push the previous Staging/Production code to the new Scratch Org
- Perform low-code development work
- Use SalesforceDX to pull a local copy of the changes made in the Scratch Org
- Convert local copy to zipped Metadata API Package (MDAPI)
- Push package to Salesforce Sandboxes
- Push package to Production Instance
That’s not a huge number of steps if you consider what all is being done, however, for the average user these steps also need to include source control and review steps. Thus the process grows a bit:
- Use SalesforceDX CLI to Connect to Production Instance
- Use git CLI to create new development branch
- Use SalesforceDX CLI to deploy new Scratch Org (with change tracking)
- Push the previous Staging/Production code to the new Scratch Org
- Perform low-code development work
- Use SalesforceDX to pull a local copy of the changes made in the Scratch Org
- Push changes to origin branch on Git server
- Trigger merge request to merge changes into Staging Sandbox
- Convert local copy to zipped Metadata API Package (MDAPI)
- Push package to Salesforce SandboxesPush package to Production Instance
Use of Deployment Scripts
To make this process quick and easy for our users we created a simple set of Python scripts that interact with both the SFDX and git binaries to accomplish the necessary tasks. All that a user needs to do (besides installing the prerequisite software) is run the script and give it a name. This name will be used to name their Scatch Org as well as their source control branch.
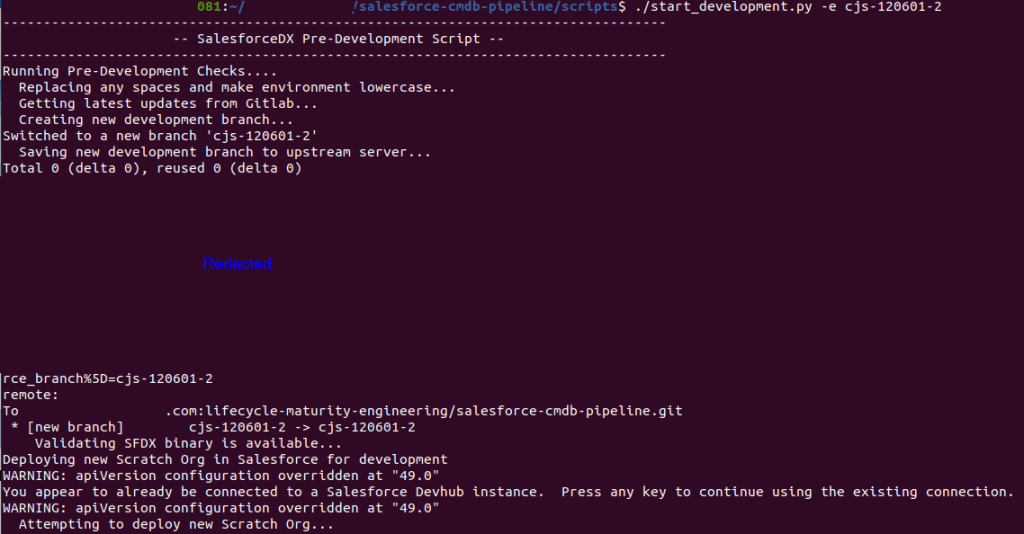
During this deployment process the script will also take the newest accepted changes (Staging branch) and apply the configuration to the new Scratch Org. This effectively gives it the feel and functionality of the Production instance, but without all the data. Some data however is required, so for that we have a collection of JSON files that are populated as well.
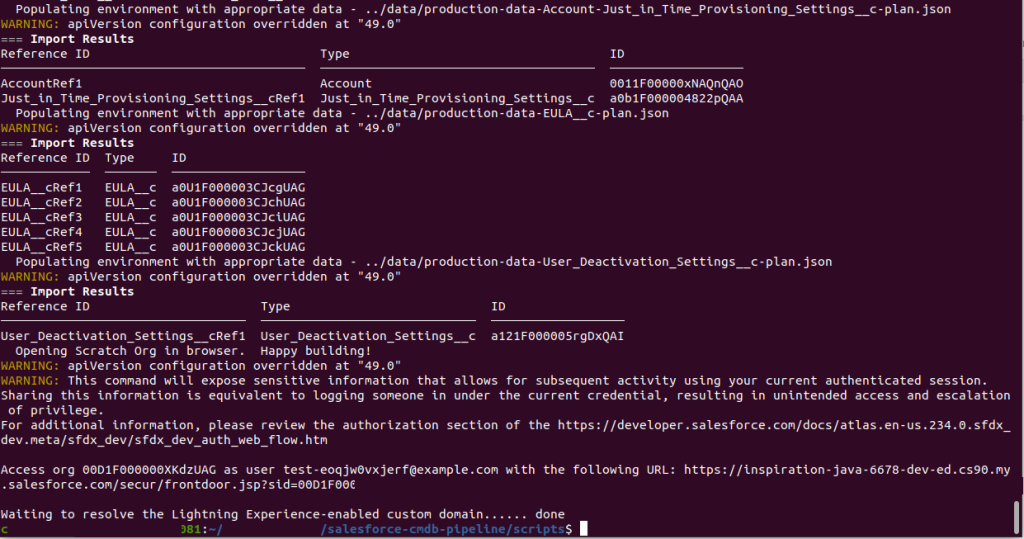
Once the process is completed the user is automatically logged into their new Scratch Org and can begin low-code development.
Use of Pre-Commit Script
Initially the I created the pre-commit script simply to simplify the process of pulling down the changes from the Scratch Org and pushing them to source control. However, this decision proved later on to be invaluable because SalesforceDX is a bit immature in many cases and required us to implement fixes on the client side before code check-in to prevent pipeline failures. Below are a couple examples
- Need to change dashboard permissions as they are assigned to Scratch Org users who don’t exist in other orgs
- Need to change the dashboard’s running context
- Need to remove the <enableAdminLoginAsAnyUser> flag from the security configuration file
- Need to remove Profiles that exist in Scratch Orgs, but not in other Orgs.
The last one is shown below as it is a very simple operation.
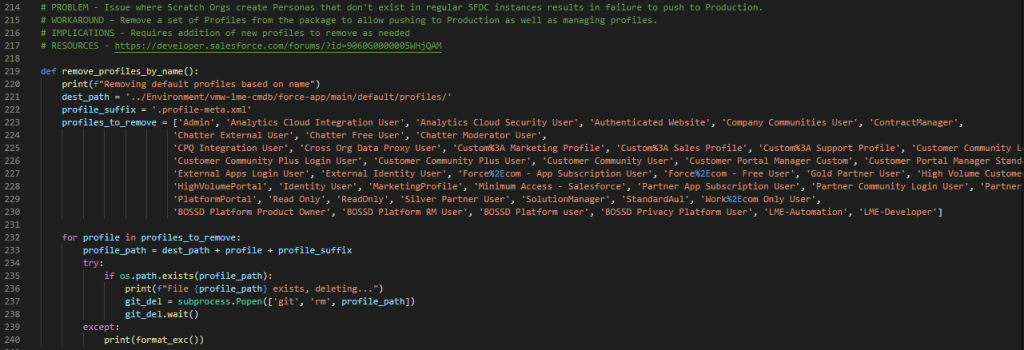
The moral of the story is that you should build in as many capabilities as possible to deal with the shortcomings of your low-code platform.
Next Up – The Road to Low-Code | CI/CD Pipeline