Note: This article is a copy of one that I have written for the compliance.engineering blog. Check it out!
In my previous article I was discussing the need for accurately describing system architecture in a way that would enable consistent discovery, documentation, and dissemination of these details across internal teams, with outside auditors, as well as with downstream consumers. This is critical, especially in the case of utilizing downstream open source packages. In this article we’ll further explore this concept of system scoping with a focus on appropriate granularity, as well as start to look at how to take a machine-readable, Infrastructure-as-Code approach that allows ongoing maintenance, automated discovery, and display of the information in various contexts. We’ll be taking all of these steps, recognizing that they are tactical decisions to enable our broader strategy of driving security and compliance efforts through a solid and sharable System Security Plan (SSP), regardless of the level of your required compliance requirements (e.g. from SOC2 to FedRAMP and beyond), or even the current maturity of your offering.
Appropriate granularity by use case
When deciding how to describe a system, it’s critical to have a clear understanding of both your audience, as well as their purposes in understanding your system. Let’s use the example of threat modeling. When performing a threat model on a system the scope can be as generic as identification of high level ports providing access to the system, or as granular as identification of all code modules and functions involved in making the incoming connection work. Providing the appropriate level of knowledge can only be attained if you have a solid understanding on the appropriate level of granularity.
In today’s organizational landscape there are many ways to describe the scope of a system. Sometimes it’s driven by outside requirements, but often it’s driven by internal processes and personal taste. Choice of tools, presentation layers, even device discovery is often left up to the individual performing the discovery. However, this is not always the case, so I’d like to briefly explore what is likely the most pedantic standard, the one in the FedRAMP Baseline SSP. If you are to look at Section 8.1 of the template you will quickly realize that the expectations are rather standardized, with sometimes even seemingly arbitrary requirements. As you start to expand this out and realize that Section 9 covers a standardized way to document and present ports and protocols information and that the FedRAMP SSP Appendix M (Integrated Inventory Workbook) has very specific requirements that build on this further at a per-device level, you can’t help but leave with a feeling that great care is put into defining the scope of these environments. PCI DSS lags behind this, but still has a very opinionated viewpoint on scope, having released their scoping guidance, as well as supplemental directions. With many examples of skilled APT intrusions, I truly wonder if some APT actors don’t have a better understanding of critical environments than some of their organizational owners. With all that said though, it’s important to realize that no matter how robust your documentation requirements are, much of this standardized approach is usable, albeit likely at a reduced granularity for every owner of an information system.
So, we know that there are varied levels of granularity, how do we choose the ideal one for our use case? Are there general principles that we can follow? I’d propose a couple for your consideration, and I promise that you will be underwhelmed. However, I firmly believe that most disasters are from cascading failures and the basic disciplines of security and compliance are the most difficult to maintain over a system’s entire, multi-year/decade lifecycle. First and without compromise, in your scoping documentation there cannot be a network boundary that is not documented and is consequently overlooked. Network boundaries, regardless if they are from the internet to a DMZ, or an internal Kubernetes namespace represent the most-critical delineation in our current world of network-connected devices. Every network boundary usually has a device that is responsible for routing, as well as security components such as firewalls or NIDS sensors. So, regardless of the perceived severity of each boundary, make sure to include it in your documentation.
Secondly, while not glamorous, asset management is the foundational pillar on which all security and compliance efforts lie. Without an accurate accounting of your assets over the entire lifecycle of the system, be it cloud accounts, VPCs, networks, physical computers, firewalls, databases, etc. you will not be able to ensure that you are running a secure and compliant environment. This foundational pillar is also the one that your audit evidence is going to stand on, ensuring that evidence collection is accurate, on-time, and that an auditor is not going to request evidence from a system that you are accidentally not correctly managing. Any plans for automated evidence collection or even a manual continuous monitoring (ConMon) hinge on an accurate inventory. Ensure that all of your assets (or types of assets) are correctly represented in your architecture information.
Varied users, varied artifacts, same data
Now that we have an idea around the appropriate levels of granularity, let’s talk about the difficulties associated with this scoping exercise. The first difficulty is the need to collect an extensive data set around your organization’s system. However, the second difficulty that closely follows is parsing that data into different views so that we don’t lose our users who need to consume the data. Let’s use an example of a basic, segmented network architecture hosting a web server to the internet via a DMZ, with a database in the internal corporate network. As you can see in Figure 1 below, this extremely simple design immediately shows complexity to a new user, and that’s even before we add in CI/CD, monitoring, telemetry, etc..
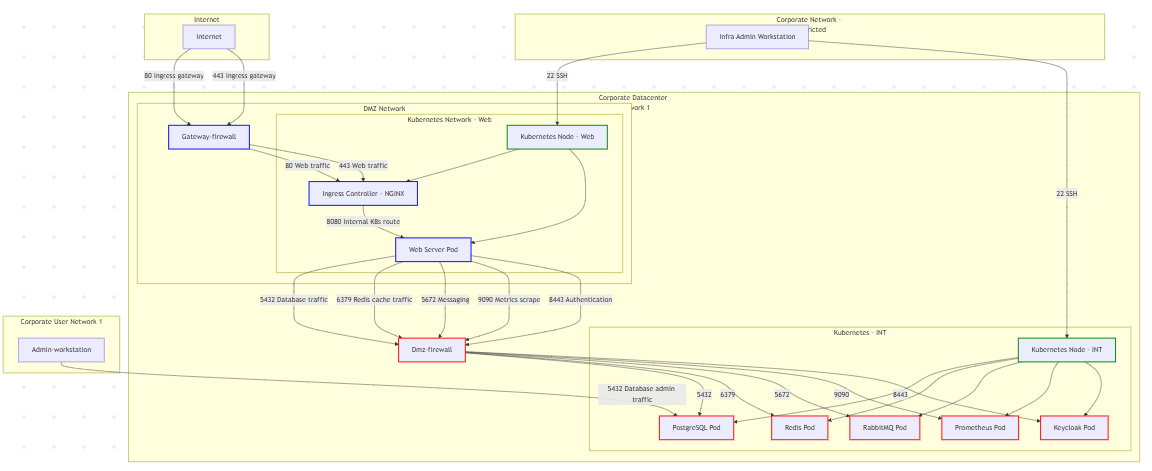
If you are sharing this information with an external resource such as a penetration testing partner, an external auditor, or even a new member of your team, it might lose them. Trust me, I’ve generated diagrams that spanned pages and pages of connections and device types (not individual devices), and until you need that level of granularity, you rapidly lose ground in your efforts to bring clarity by losing your audience during the initial introduction to the system. Clawing your way back up out of that lost audience can almost be overwhelming and force you back to an overly-simplistic presentation of the system.
The question then stands, do we need to have such a complex diagram? Yes, from a security and compliance perspective it’s critical that everyone reading your System Security Plan (SSP) has all the details necessary to make the associated security and compliance-related decisions. At this point hopefully you realize that we must start to plan for varied audiences, but they must use the same underlying data. Examine Figure 2 below as what I would consider an adequate high-level summary of the same system in Figure 1; but staying true to clarity and network boundary awareness, but minimizing overwhelming details until later.
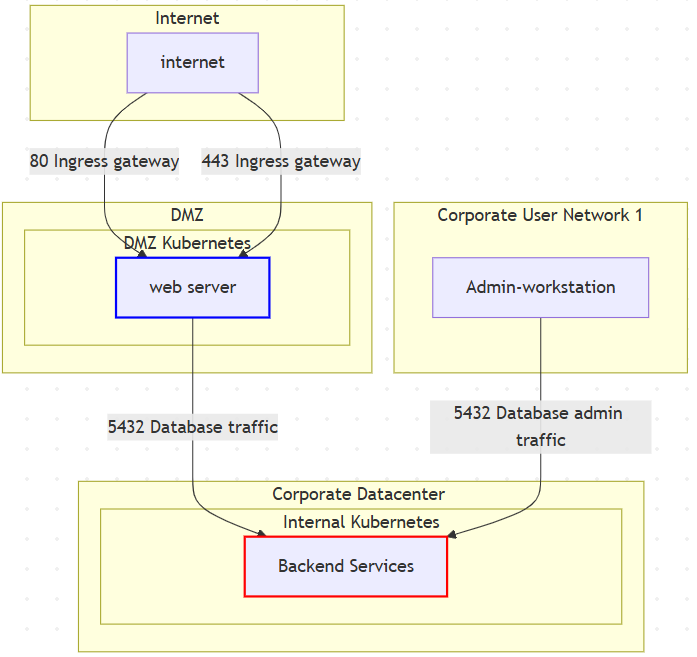
As you can see in Figure 2, the fundamentals are mostly there, and a user can, at a glance, identify the core device types, traffic flows, as well as observing the network-based breadcrumbs, intentionally-implied network boundaries where an individual in security or compliance would naturally expect the presence of firewalls or other boundary monitoring devices. Once they have this basic picture in their mind, then they are enabled to dive in deeply and understand the system’s specifics as they relate to your listener’s involvement, but in this case with them easily following along. The deep-dive that follows then adds in visibility for supporting services, CI/CD, monitoring, logging and telemetry, security tools, etc. as the situation warrants.
We’ve discussed this from a security and compliance viewpoint, however, knowing your audience will enable you to effectively re-use the data in other contexts as well. Here’s a couple other personas and attributes that you would likely want to focus on in your architecture diagrams to benefit each role:
- Enterprise Architect
- High-level component visibility – clarity on all major systems, platforms, and integrations.
- System boundaries and data flows – essential for compliance, data governance, and risk assessments.
- Technology stack standardization – shows which technologies are used, aiding strategic planning and tech rationalization.
- DevOps Engineer
- Deployment topology – understanding where and how services run (e.g., Kubernetes, serverless, VM).
- Integration points and APIs – visibility into service interconnectivity for monitoring and troubleshooting.
- Runtime environments and infrastructure dependencies – identifies containers, storage, networking, and scaling requirements.
- Infrastructure Manager / Network Engineer
- Network topology and segmentation – VLANs, subnets, firewall rules, and routing paths.
- Redundancy and failover – visibility into HA setups, load balancers, and DR strategies.
- Bandwidth and latency constraints – for capacity planning and performance tuning.
Mindfulness of operational security
If we’re honest, the only individuals reading your System Security Plan (SSP) are likely those maintaining or assessing it, while everyone else is just trying to find out applicable details related to their role. I don’t blame them, who wants to read 800 pages describing a system when they just need to understand the specific details on Page 143? That said, it’s imperative to understand that the other person who wants to read your SSP is your attacker. Due to the nature of its contents, the SSP (along with any other architecture, deployment, configuration, operational documentation) is a treasure trove to the potential attacker. With this in mind, you need to take pains to not only collect and maintain holistic and accurate data, but also to make sure that good operational security restricts viewing and updating those contents to only a select few who need access.
There’s also a second aspect here that we must be mindful of, and that’s the tools that we’re using to do discovery and documentation. You have likely noticed that the diagrams in this document are generated using Mermaid, thus making Architecture-Documentation-as-Code a reality. However, using this as an example, you’re not going to want to submit your highly-sensitive data to Mermaid Live to easily generate your diagrams due to the possibility of the information leaking out and being tied to your organization. Make sure that you trust all of your tools and when in doubt, run an internal copy and restrict it from outside communications.
Universal baseline documentation
We’ve talked about the need for holistic scoping information, but also the need to produce multiple outputs (or views) from the same data. This now places us in what can easily degrade into a split-brain situation, where an organization is likely to experience drift between two sets of documentation. Because of this, it’s critical that we realize that we’re not managing two different data sets, but instead we must manage a single, extremely-detailed data set that supports multiple presentation viewpoints. This brings a host of challenges though, especially when you expand your strategic scope to understand that you’re going to need the underlying open source packages that support your system to have a compatible baseline documentation. Another obvious challenge is how are we going to standardize on something that everyone can use and isn’t subject to vendor lock-in? If you’re already involved in this space, you will probably successfully guess that we’re going to be investigating the possibilities here, including using the NIST Open Security Controls Assessment Language (OSCAL). Much like the security issues that have brought about the Software Bill of Materials (SBOM) and Vulnerability Exploitability Exchange (VEX) as standardized approaches to share security knowledge, it’s clear that we need to have an equivalent for the compliance space if we have any chance of Policy-as-Code to be effectively used… Let’s see what those options are, and where they potentially lead us.