In my first comparative analysis of local LLMs I looked at Using a Local LLM | Function-Level Code Generation and Accuracy. As I continue my investigation into the use of a local LLM on commodity hardware (specifically an RTX 5070 TI), I want to evaluate how each of the models does when analyzing source code (in this case assessing Golang code in a couple files underlying Minio). My goal here is to determine which models can draw out accurate details from a code base and present them in a meaningful way. As before, I am using a small testing set of three prompts, spread against 11 models. Each of these prompts (one of which is below) is sent to all of the models, with the responses being reviewed and finally scored by a foundation model.
As shown below in Gemma3‘s response to the above prompt, the amount of details can be somewhat extensive. In this case, looking at the acl-handlers.go code.

Scoring, as done previously, is on a 1-10 scale, with 10 being the ideal score as determined by the foundation model. As before, we have some clear winners, though in general many of the models performed admirably. Not surprisingly, three of the four top performing models have the term “coder” in their name. The overall results are shown below.
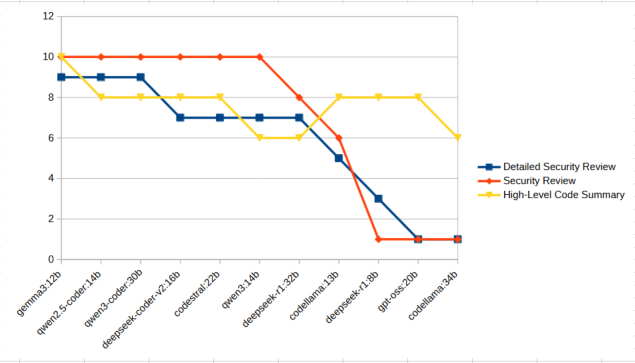
Gemma3 was previously seen to have a pretty decent score at code generation, however, in this case it is at 1st place, even with tight competition. The Qwen/Deepseek coder family of models is close behind, with all tasks scoring high marks for these models. Observed hallucinations with these models was also low, with Gemma3 and Qwen2.5-Coder:14b not hallucinating at all. Qwen3-coder:30b, GPT-OSS:20b, and Codellama:34b all had hallucinations in 1/3 of the tasks. Qwen3:14b and Codellama:13b each hallucinated on 2/3 of the tasks. This leaves Deepseek-R1, both the 8b and 32b parameter models each hallucinating on every one of the code analysis tasks. Deepseek-R1:8b doing so in a spectacular, totally-lost-it’s-entire-mind sort of way on one of the tasks.
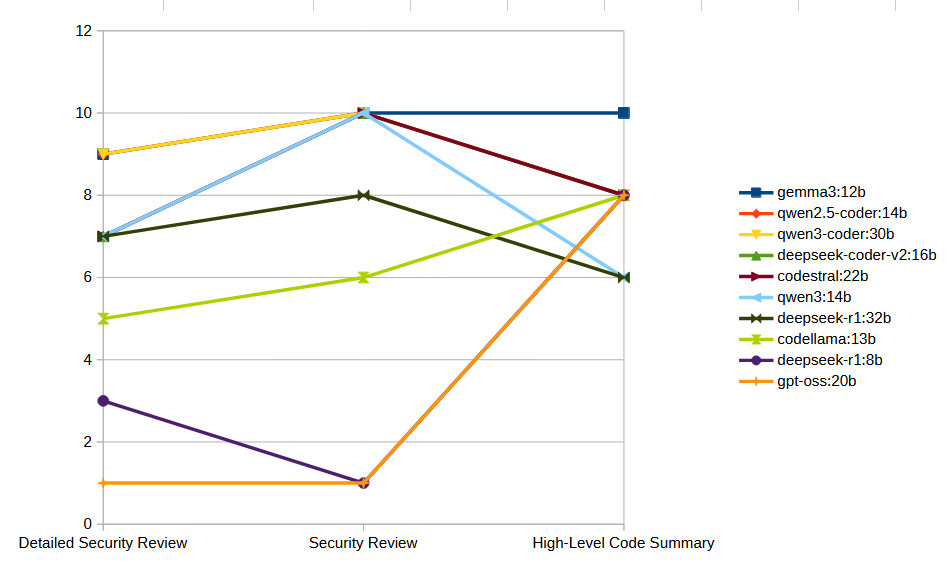
Looking at the scores with a per-task view, it’s pretty clear that GPT-OSS:20b, Deepseek-R1:8b, and Codellama:13b don’t seem to have their niche in this use case. That’s a bummer, since the GPT-OSS scored so highly in my last test. It is noteworthy though that part of the impact to the score is that the GPT-OSS model occasionally returns a blank result. I’ve seen it several times now, where the model will not return any response data to certain queries.
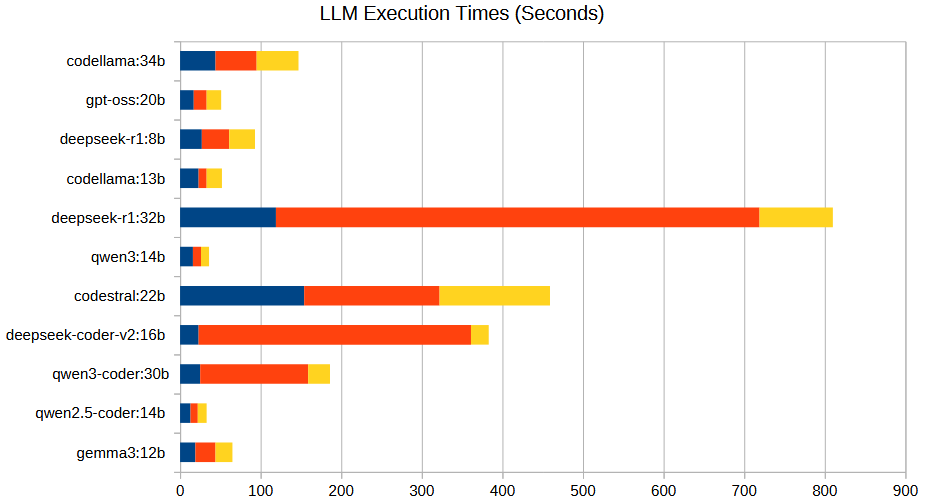
The scores above take no consideration into the execution time of each model. That score is based entirely on accuracy of the response from the model as judged by a foundation model. However, as you can see from the graph below, there is a significant time difference experienced when using the various models. Happily though, our top quality performers (Gemma3 and Qwen2.5-coder) are also some of the most time-efficient models.
Model-by-Model Notes
As before, here’s some observations made by a foundation model on each of these local LLM’s performance during testing.
qwen3:14b / qwen2.5-coder:14b / qwen3-coder — Reliable and format-faithful.
- Trend: Strong in both early (router) and ACL runs; low hallucinations.
- Strengths: Clean section coverage; stays within context.
- Weaknesses: Sometimes light on MinIO’s PBAC vs ACL nuance unless highly signposted.
gemma3:12b — Accurate and concise.
- Trend: Good on router; steady on ACL prompt.
- Strengths: Strong high-level accuracy; low hallucinations.
- Weaknesses: Can be a bit generic on logging/monitoring specifics.
deepseek-coder-v2:16b — Structured and grounded.
- Trend: Solid across prompts; low speculative content.
- Strengths: Good security-surface coverage; decent specificity.
- Weaknesses: When context is thin, leans general rather than file-specific.
codestral:22b — Consistent top-tier.
- Trend: High accuracy across both router and ACL contexts; adheres to structure.
- Strengths: Grounded, low hallucination rate.
- Weaknesses: Occasionally boilerplate phrasing.
deepseek-r1:32b — Detailed but occasionally speculative.
- Trend: Provides depth; can drift into features not in the handlers.
- Strengths: Thorough technical write-ups.
- Weaknesses: Periodic over-claims (e.g., encryption/TLS/KMS or identity systems) and misstatements about ACL support.
codellama:13b — Capable but uneven.
- Trend: Picks up MinIO/S3 concepts; accuracy varies.
- Strengths: Reasonable structure; recognizes buckets/objects.
- Weaknesses: Over-asserts ACL/encryption in handler; misses PBAC; thin sections at times.
deepseek-r1:8b — Unreliable format/grounding.
- Trend: Formatting and meta-text issues; garbled fragments surfaced.
- Strengths: Occasionally names relevant components.
- Weaknesses: Elevated hallucinations; poor adherence to prompt formatting.
codellama:34b — Operationally unreliable.
- Trend: Timeouts/no usable content.
- Weaknesses: Not suitable for this workflow.
gpt-oss:20b — No response path.
- Trend: “No response” behavior means no utility here.
So, as you adventure forward and need to do some source code analysis, feel free to check out Gemma3 and Qwen2.5-coder and find out if they are the right fit for your use case!