As part of investigating the use of a local LLM on commodity hardware (specifically on an RTX 5070 TI), I wanted to step away from the more standardized testing (e.g., LiveCodeBench) and do a highly-unscientific, gut-check on what to expect. I mean, in the real world, what do those scoring numbers actually translate to as someone who needs to write and validate code? What about performance in other task areas, such as data translation or formatting jobs? To accomplish this highly-subjective testing I created multiple, standardized prompts and then sent them to a selection of 10 locally-hosted models. The results were then manually reviewed, as well as automatically reviewed by a foundation model to provide the numeric score and additional comments. From Deepseek-R1, to Codellama, my goal was to understand which one is ideal for my various use cases.
Today, I will focus solely on the function-level code operations spawning from prompts to create an entire Python function. To do a small sample set of testing I came up with three representative scenarios. The first to scrape the contents of a website, the second to query a table in a PostgreSQL database, and the third being a more obscure/vague prompt to create a listening gRPC Server. The models that I tested are:
- gemma3:12b
- deepseek-coder-v2:16b
- gpt-oss:20b
- deepseek-r1:8b
- deepseek-r1:32b
- codellama:13b
- codellama:34b
- codestral:22b
- qwen3:14b
- qwen2.5-coder:14b
The overall scoring is on a scale of 1-10, with 10 being the best performing against this very small, yet representative sample set. As is shown by the data below, there is sometimes significant variance in model capabilities (e.g., codellama 34B), or consistent, but middle-of-the-road scores (e.g., Deepseek R1:32b). However, there were also a couple leaders with consistent, but also high-quality answers…
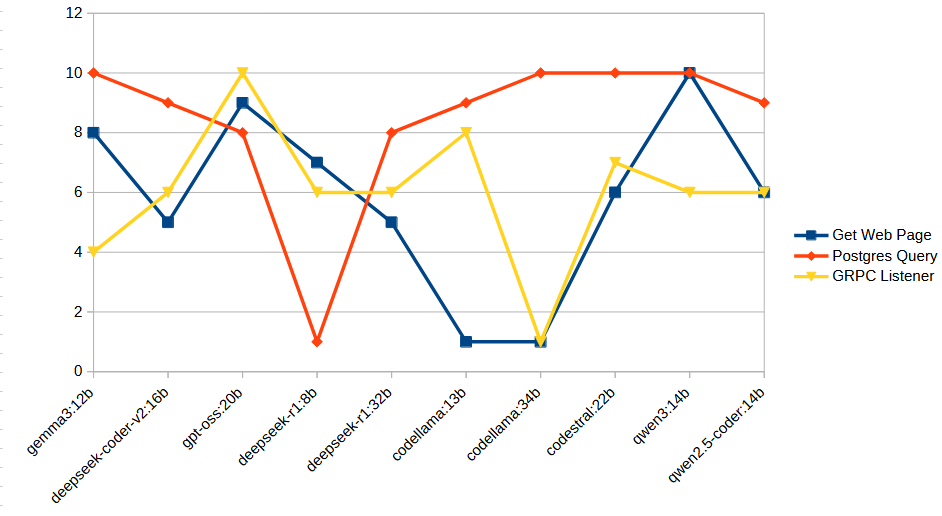
If you flip the presentation to be focused per-task you can see that ironically, the best responses were generally around the connection and querying of Postgres. This is ironic, because it’s also the response that involved significantly more code being generated than the other two tasks.
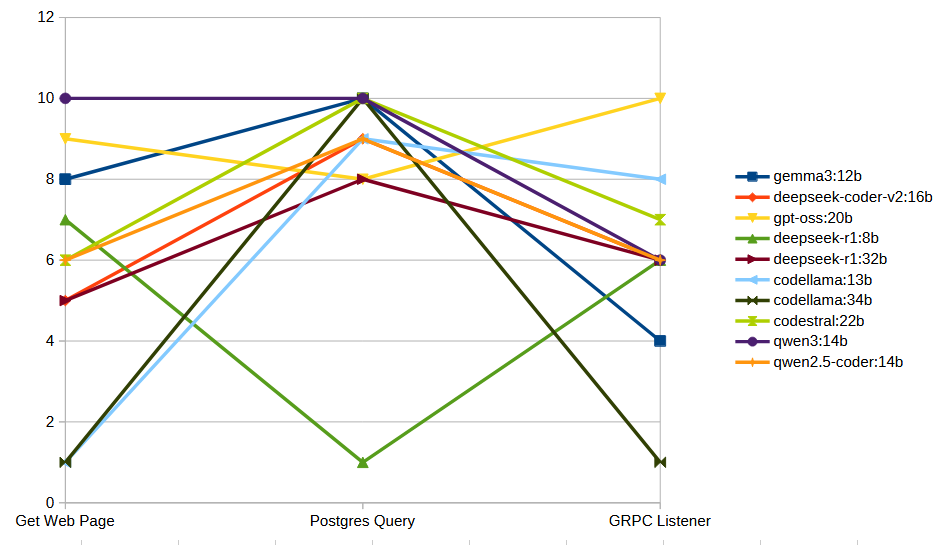
A tabular form of the scores is below:
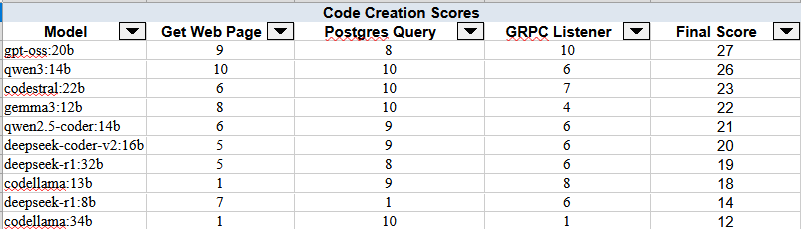
I left this exercise with a couple key observations:
- Qwen3:14B was the only model to score a 10 twice. While it’s final score was one point behind GPT-OSS, the dataset is pretty small to do anything more than a high-level survey…
- Hallucinations were detected, but not as often as you might suspect.
- Codellama:13B was flagged 2/3 times for hallucinations, including on the simple function to scrape a web page. I have thus far been underwhelmed by this model, as well as it’s larger counterpart.
- Deepseek:8B and GPT-OSS:20B were each flagged 1/3 times for hallucinations. That single hallucination severely impacted the Deepseek-R1:8B’s score. Without that, it would have been a top performer. As a side note, in general, the 8 billion parameter model seems to perform better in many areas that the larger 32B model.
- Almost every model is overly chatty, offering advice and implementation guidance, even when you ask for it to be omitted. I pretty much expect that at this point, where you need one prompt to generate your output, and a second to clean it up to only contain code that is ready for ingestion by another process.
- Gemma3 pleasantly surprised me with its capabilities across the board. However, during my own review it interestingly enough was the only model that has code which relies on an obviously foreign (and somewhat obscure) module. This is a reminder that you cannot just programmatically determine to not use a model like Deepseek and assume that you are safe from any specific type of model behavior. AI usage is a tool with an accompanying human behavior pattern, not a plug-and-play solution. Previously, employers would hire an individual for their knowledge; in the future, it should focus more on their discernment.
AI usage is a tool with an accompanying human behavior pattern, not a plug-and-play solution. Previously, employers would hire an individual for their knowledge; in the future, it should focus more on their discernment.
- Deepseek-Coder-v2 ironically appears to have generated code for the gRPC task using a snippet from a Github issue… Specifically, https://github.com/grpc/grpc/issues/33829. Yet another reminder that AI will try to help, but it’s not all-knowing…
Model-by-model notes
Here’s some observations on the results as made by a foundation model regarding each model’s performance during the testing.
qwen3:14b
- Performance: HTTP 10, PG 10, gRPC 8 (avg ~9.3). Consistently returns solid, runnable code with good error handling.
- Issues: Occasionally omits explicit retries; gRPC pieces are correct but minimalist.
- Recommendations: Add retry/backoff helpers (e.g.,
tenacity) and ensure gRPC includes a clean start/termination block every time.
gpt-oss:20b
- Performance: HTTP 9, PG 8, gRPC 10 (avg ~9.0). Best gRPC server shape (binds
:8080, starts, blocks). - Issues: One PG hallucination (e.g., import/API mismatch) flagged.
- Recommendations: Lock PG to
psycopg2(orpsycopg v3) with verified imports; add parameterized queries + retries.
codestral:22b
- Performance: HTTP 6, PG 10, gRPC 7 (avg ~7.7). Excellent DB code quality; servers are fine.
- Issues: HTTP solutions can be under-featured (timeouts/status checks sometimes missing).
- Recommendations: Standardize HTTP template:
requests.get(..., timeout=10); raise_for_status();return body—not print.
gemma3:12b
- Performance: HTTP 8, PG 10, gRPC 4 (avg ~7.3). Strong DB; HTTP good.
- Issues: gRPC often misses full start/wait loop or minimal server boilerplate.
- Recommendations: Include
grpc.server(ThreadPoolExecutor()),add_insecure_port("0.0.0.0:8080"),start()+wait_for_termination().
qwen2.5-coder:14b
- Performance: HTTP 6, PG 9, gRPC 6 (avg ~7.0). Balanced outputs, DB is solid.
- Issues: Tends to use generic
exceptand may not output results explicitly. - Recommendations: Prefer library-specific exceptions, and ensure explicit
return/printof results.
deepseek-coder-v2:16b
- Performance: HTTP 5, PG 9, gRPC 6 (avg ~6.7). Good PG code paths.
- Issues: HTTP/gRPC often minimal; missing retries and crisp status/timeout patterns.
- Recommendations: Add reusable decorators for retry/backoff; enforce status checks/timeouts in HTTP.
deepseek-r1:32b
- Performance: HTTP 5, PG 8, gRPC 6 (avg ~6.3). Generally acceptable with room to harden.
- Issues: Error handling and cleanup can be inconsistent; sometimes under-specifies outputs.
- Recommendations: Normalize: (PG) parameterized query + cursor/conn cleanup; (HTTP) timeout/status; (gRPC) explicit start/wait.
codellama:13b
- Performance: HTTP 1, PG 9, gRPC 8 (avg ~6.0). Big spread—DB and gRPC good, HTTP notably weak.
- Issues: Occasional hallucinations (missing imports / odd APIs) and instruction adherence problems in HTTP.
- Recommendations: Use strict import scaffolds/snippets; add a final lint/parse pass to catch missing imports.
deepseek-r1:8b
- Performance: HTTP 7, PG 1, gRPC 6 (avg ~4.7). HTTP/gRPC acceptable; PG is the outlier.
- Issues: PG frequently lacks error handling/retries/outputs; occasional hallucination.
- Recommendations: Adopt a vetted PG template: verified imports,
try/except (OperationalError), parameterizedSELECT * FROM users, fetch + return/print, and retry.
codellama:34b
- Performance: HTTP 1, PG 10, gRPC 1 (avg ~4.0). Excellent DB, very weak elsewhere.
- Issues: HTTP/gRPC often miss core requirements (binding/starting or returning body).
- Recommendations: Provide strict task checklists per prompt; add unit smoke tests (AST parse, port bind check, return/print presence).
So, if you’re wondering what local model you should be using for smaller, code generation tasks, check out GPT-OSS and Qwen3 to see if they work for you and your use case.