I’m pretty inexperienced when it comes to Fluentd logging, but I have a necessary use case to use it to ingest some log files with a non-standard format. There’s documentation on how parsers work, and there are even examples of how it should automatically happen. But, then there’s also the reality that I discovered that not all uses and integrations work like you would hope. This is a readout of my hours-long journey trying to sort this all out and successfully ingest an AWS SSM Agent Log. Side note, if you run AWS EC2 instances, you should be aware of the powerful capabilities that SSM provides, and log the activities accordingly.
Ok, first step is to tail the agent log at /var/log/amazon/ssm/amazon-ssm-agent.log. This instances happens to be a Fluentd docker container, so the path is slightly different due to the host mapping. As part of this no logs are ingested, because they cannot be parsed. The log format is shown below for reference.
2025-02-28 00:40:33.7314 INFO Agent will take identity from EC2
2025-02-28 00:40:33.7314 INFO [ssm-session-worker] [test-user-ssm-x3bigaj6ieo8fi6bduivlujnnu] Init the cloudwatchlogs publisherStep two, involved creating a parser (below), which attempted to set the timestamp using a variety of settings for time_key, time_format, and keep_time_key. If you omit keep_time_key, the logs are forwarded, but without a timestamp and are largely worthless.
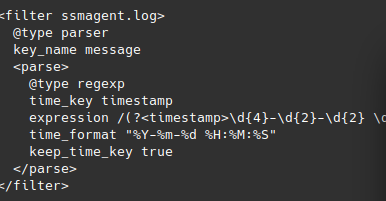
During this effort I discovered that it was extremely valuable to use a test Ruby function to validate the time_format was correct. A list of each setting is available here. Fluentd uses Ruby’s Time.strptime function to create the timestamp. Below you can see a quick test, with a successful output on the right.

However, with this configuration I still receive an error message that ‘Rejected by Elasticsearch… failed to parse field [timestamp] of type [date]’.

After much trial and error, at this point I think that I understand a few things:
- timestamp is a reserved variable for Elasticsearch (my logging destination).
- Elasticsearch expects the timestamp to be in a certain format, which is ISO 8601.
- Setting the time_format appears to have no impact on correcting this issue natively.
To proceed, I change the variable name for the original timestamp to be named log_time instead.
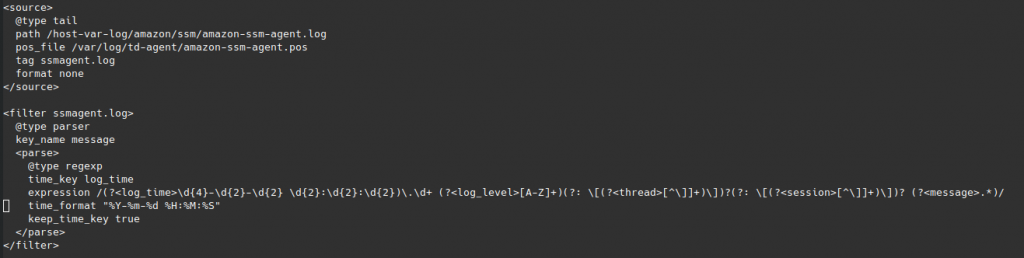
This allowed me some further progress, with events now being sent to Elasticsearch and successfully ingested with a tag for the log_time, however, still no timestamp in Elasticsearch to allow a time-based view of events.
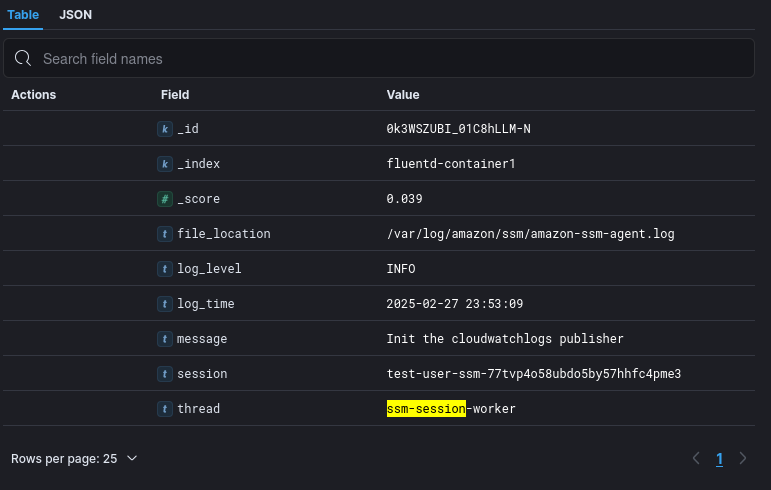
After trying many different ways to sort out the various parsing errors, I came to the conclusion that the problem was not with Fluentd’s parser, but with my Elasticsearch destination. To resolve this I came up with a one-line Ruby script to parse the log_time value into ISO 8601 format. Below you can see that being tested.

The final result is below, where the input parser sets the variables for each log entry, then a record transformer takes the log_time and saves the ISO 8601 value as a new timestamp variable so that Elasticsearch is happy.
<source>
@type tail
path /host-var-log/amazon/ssm/amazon-ssm-agent.log
pos_file /var/log/td-agent/amazon-ssm-agent.pos
tag ssmagent.log
format none
</source>
<filter ssmagent.log>
@type parser
key_name message
<parse>
@type regexp
expression /(?<log_time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})\.\d+ (?<log_level>[A-Z]+)(?: \[(?<thread>[^\]]+)\])?(?: \[(?<session>[^\]]+)\])? (?<message>.*)/
</parse>
</filter>
<filter ssmagent.log>
@type record_transformer
enable_ruby true
<record>
file_location "/var/log/amazon/ssm/amazon-ssm-agent.log"
timestamp ${Time.parse(record["log_time"]).iso8601}
</record>
</filter>
## DOCS: https://docs.fluentd.org/output/elasticsearch
<match system.* wazuh.* ssmagent.*>
@type elasticsearch
host "192.168.1.106"
port 9200
...Now, the events are received with a valid timestamp, and support time-based operations in Elasticsearch.
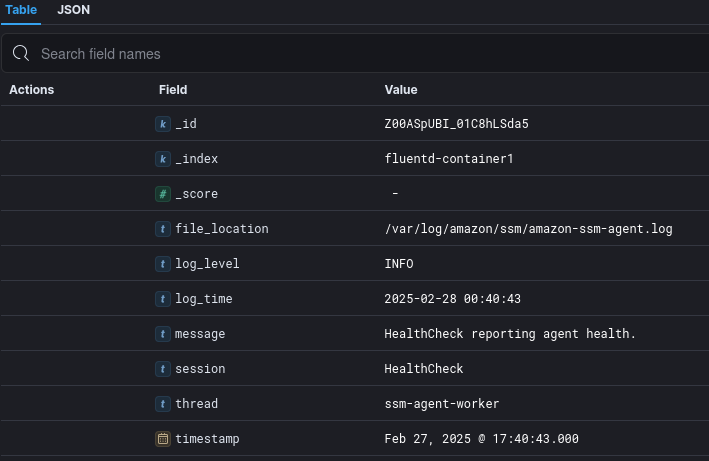
I’m curious what the performance impact of this would be at scale, however, that’s a problem for another day. This journey has been unexpectedly long, and who knows, maybe I found the long way, or the wrong way to solve the problem. Until I find out a better alternative though, this is a way to solve the problem of non-standard log formats and an Elasticsearch server.