A while ago I had the opportunity to explore the use of Retrieval-Augmented Generation (RAG) with the use of both internal and public LLMs, including various GPT and Llama models. The opportunities here are extensive, both for good, as well as harm if not implemented with proper oversight. Here’s a high level overview of that effort, as well as some observations as someone who is not an expert in the realm of AI and RAG. I won’t cover the getting started type of materials here, however, I’ve included some helpful resources at the end if you need to brush up or learn something prerequisite to understanding the below.
Tooling and Requirements
Data Storage
One of the largest difficulties for using a LLM with RAG is that you need to ensure that you are only referencing accurate data. This is especially important when working with technical data, where the answer to your question will likely vary from release to release. Because of this, it’s important that you have a way to easily tag embeddings for removal later on. To accomplish this I have utilized PGVector as my vector database, but have modified the table structure as you’ll see below. This, accompanied with indexing (HNSW – vector_l2_ops) improves query times, but still with an expectation of .98 neighbor accuracy.
Data Handling
All creation and manipulation of data is done using Langchain and Sentence-Transformers with code written in Python. You can expand on your usecase as much as desired, including adding functionality to read PDFs, .DOCX, and other document formats.
RAG Content Handling
Creating Content
The first step in creating RAG content is to take data (e.g., documents or other text) and convert it into vectors. In this case, I used sentence-transformers all-MiniLM-L6-v2 model, which provides a 384-dimensional vector to each chunk. There are various ways (including a split_documents function) to chunk up your data, but after some testing I settled on the approach of saving it per page to a list, which was then chunked up in approximately 200 token chunks, with a customized overlap. This can then be saved to the Postgres database using the PGVector embedding_function of the above model, then finally using the add_texts function to save it to the database.
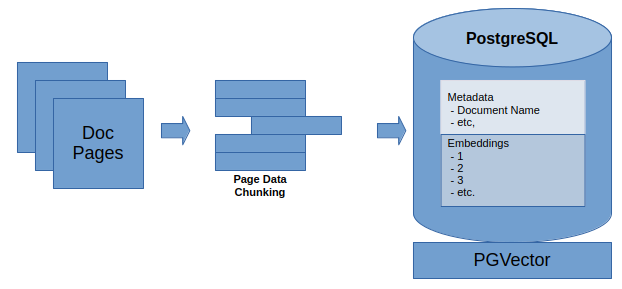
Tuning Results
Tuning your chunks are critical to having a viable result. In this example, we want to have enough context in our chunks to provide a useful response, but based on limitation in token size, must have managed sizes to allow multiple embeddings to be returned. In testing, I ended up settling on an embedding size that allowed for the return of around half-dozen documents, with each being limited to around 500 tokens. With a minimally-defined overlap, this seemed to provide appropriate result coverage. All of these results are gathered using the similarity_search_with_score function. Having the RAG results in hand, I can now use the Langchain ConversationChain.predict function with the original query, as well as additional [RAG] context.
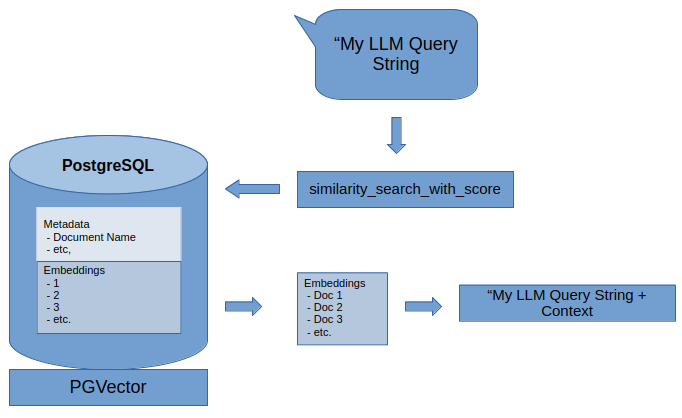
Removing Stale Content
To be able to remove obsolete content we are able to utilize our Postgres functionality to call a delete command to remove all embeddings related to a specific document.
Configuration and Deployment
Prompts
As with any interaction with an LLM, natural language and appropriate context is critical. A significant part of this is in how you describe your desired persona. In this exercise there were multiple personas identified, with varying degrees of technical expertise. An option in the UI enabled the requesting user to select the appropriate persona.
Observations
Separate your calls (operation vs. formatting)
I discovered that it is important to be able to make multiple queries to the LLM to determine the final, formatted answer. If you try to put too much instruction in a single command, your original answer is often polluted. Because of this I ended up doing a two-query approach, the first to determine my answer, the second purely to format it in the appropriate manner and towards the intended audience.
Garbage-in-and-garbage-out
The largest lesson learned from this exercise is that unless you have proper documentation, and properly-formatted documentation, you will largely have erroneous results. Put in general terms, if you have generic documentation, you can generally expect to have partially-accurate coverage. However, this coverage tended to become more specific and detailed, but misleading. It’s only after updating source documentation to have definitive statements in natural language that result coverage improved to providing some good answers. Hallucinations however remained, with detailed explanations that simply did not match reality.
Risk of false confidence and need for governance
LLMs can and are a powerful tool in the arsenal of anyone with access, with is generally most of the world at this point. Whatever the term would be for blindly following a well-informed and persuasive speaker finds an appropriate home at the door of danger associated with LLM usage. While generative AI does draw on the wisdom of millions of individuals, it is also mathematical logic of choosing word sequences in the most logical manner; with information beyond our visibility in choosing that text. Generative AI also appropriately reflects human mannerisms in it’s authoritative answers, often with a completely wrong and inaccurate result. Thus, it should be carefully evaluated to understand what level of blind trust should be allowed when relying on its content, even content that you have augmented via RAG.